






Do we have a problem with the term "VideoAI"?
What are we searching
for with VideoAI?
*Updated...thanks SORA!
Well let's start with 2023. The evolution of VideoAI
2023 marked an unprecedented surge in GenAI content tools and processes, across the breathe of creative disciplines (Imagery, video, music, 3D, and voice).
But its the moving assets where we saw the most unfulfilled potential for growth.
We went from a landscape devoid of public text-to-video models at the beginning of the year, to browser tabs overflowing with dozens of video generation platforms, and hacks and experiments giving way to commercial tools and levels of hacked temporal coherence.
Most of these commercial tools use tokenised "GPU time" to enable users to generate brief video 'clips' from textual or visual prompts - currently, we're capable of producing videos lasting about 4 seconds with variable quality and pacing challenges, and like most early image tools we're struggling with consistency. BUT we're asking for 24+ frames every single second - so its to be expected. VideoAI platforms utilising video chatbots, avatars, dubbing, and deepfakes are far more stable - but with limited creative freedom.
Despite these limitations, the advancements in video generation in 2023 has hinted at the onset of a major shift, reminiscent of the revolution witnessed in image generation. With continuous enhancements in text-to-video technology and the emergence of new models, methods, and functionality like multi modality, image-to-video, video-to-video, and motion control specificity.
To navigate through this burgeoning domain of innovation, we're continually monitoring significant progress, building node based scalable solutions, and liaising with emerging companies - to enhance, improve, and develop the video generation landscape with a targeted goal.
But the biggest issue we have found is what to call all of this new stuff! Let's have a look:

Classifying the
meaning of "VideoAI"
What does "VideoAI" mean?
What is a videoAI company in 2024?
When I was reviewing companies and services for this article, I've noticed a lack of focus and direction in defining where or who each product is targeted towards. This is not a uniquely "video or AI" problem in the start-up world, its something that scaling start-ups often struggle with in defining who their ideal client and consumer are, and why this product will help them? So, I popped my SEO hat on and got to work analysing the keyword clusters, competition, and LSI surrounding the term "VideoAI".
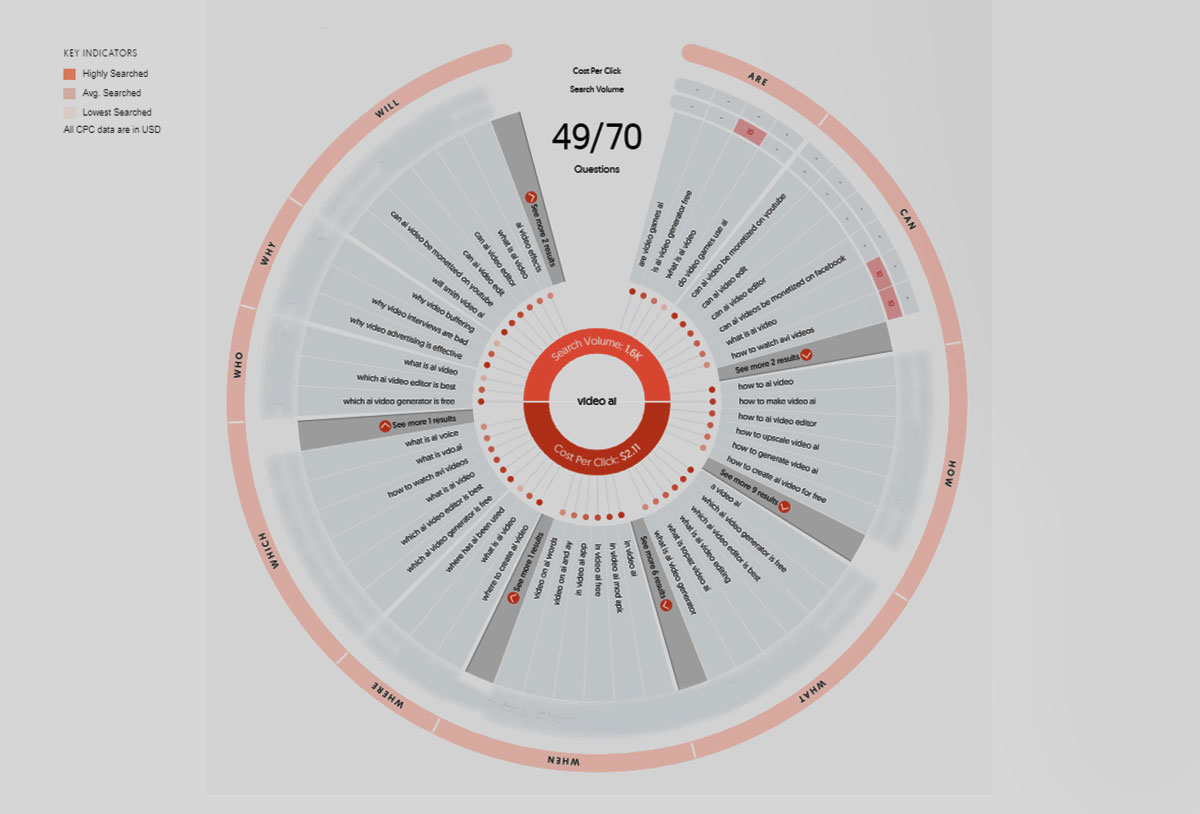

Essentially, this is content strategy 101 right? What are the contextual demands of my product, and how do my content pillars reveal the answer to the consumer?
And when your consumer is an agency, production company or brand - you need to identify with their immediate need, and the eventual viewer too!
So what's VideoAI for, and how are content creators / producers going to find it to engage with it?
VideoAI is being used as a collective term for "all genres of AI video content generation" - but like "content" - video encompasses such a wide range of services, solutions, & specialisms, its worth starting with a subcategory classification of what we're reviewing:

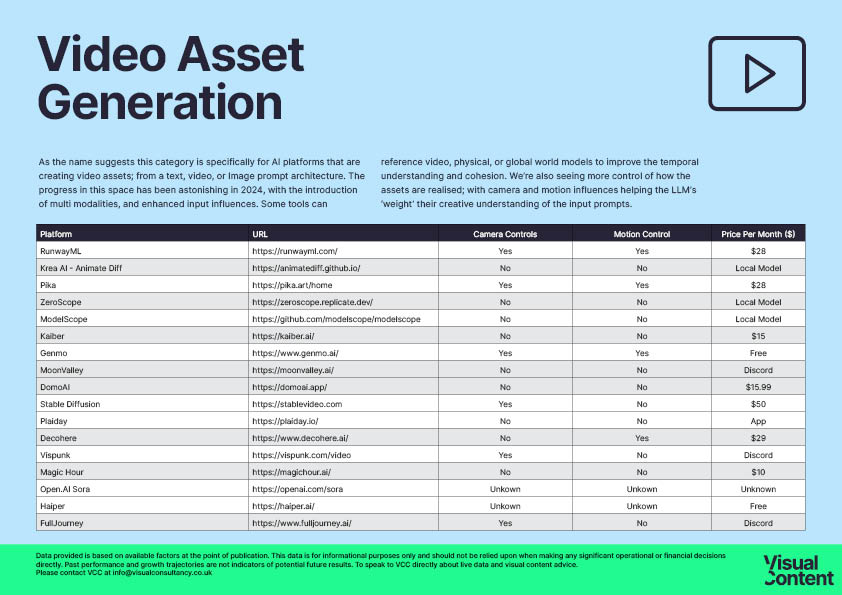
Video Asset Generation

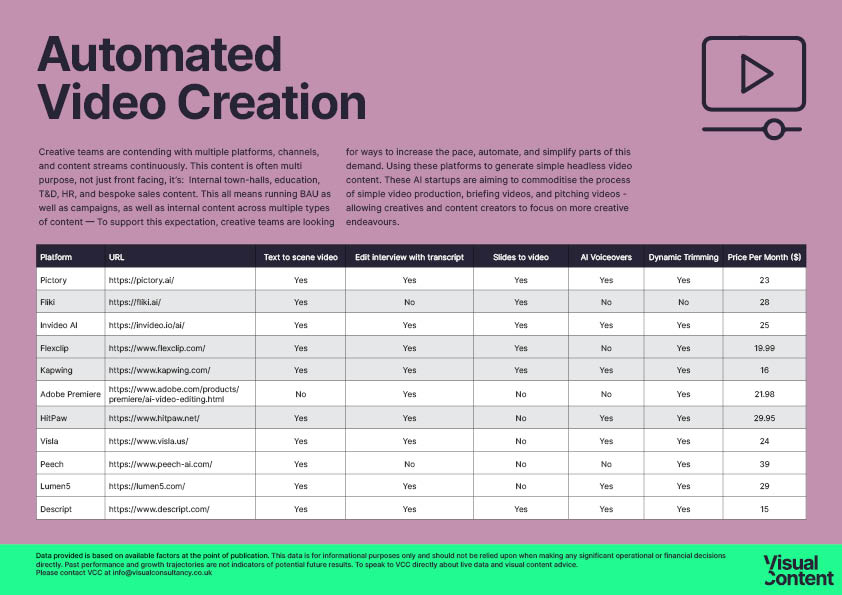
Automated videos

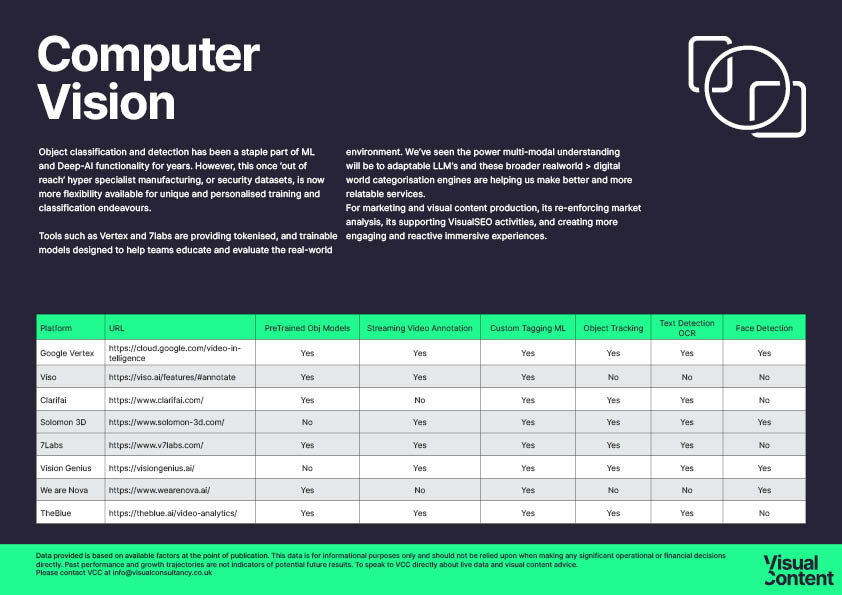
Computer Vision

Multifunctional VideoAI

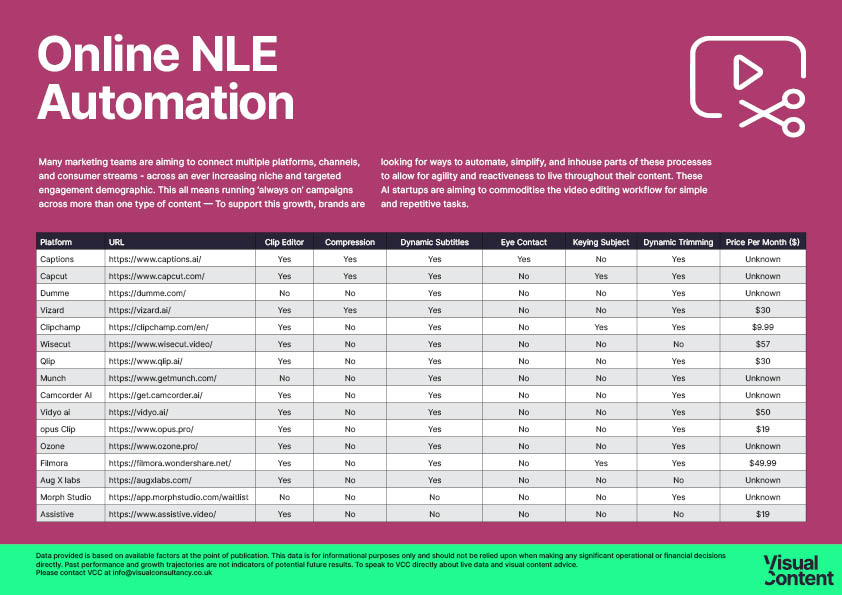
Online NLE Automation

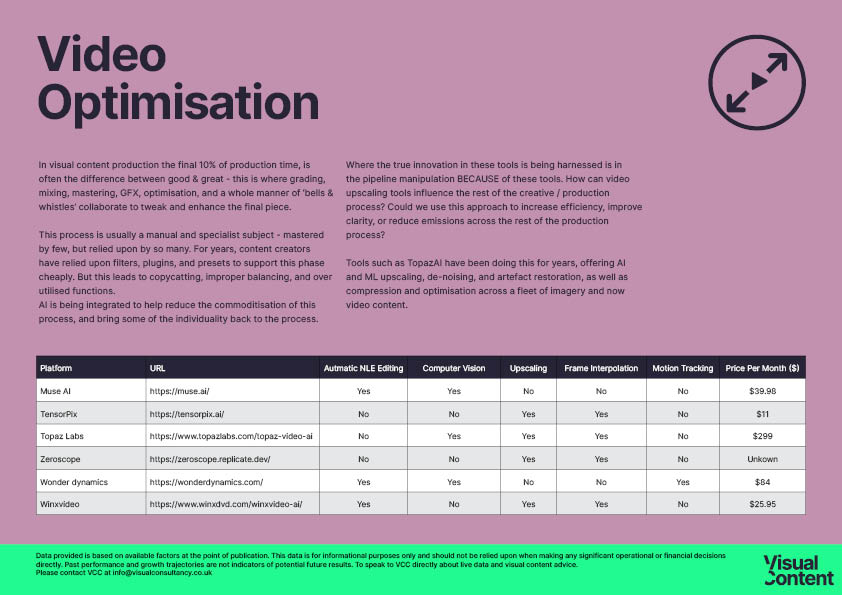
Video Optimisation
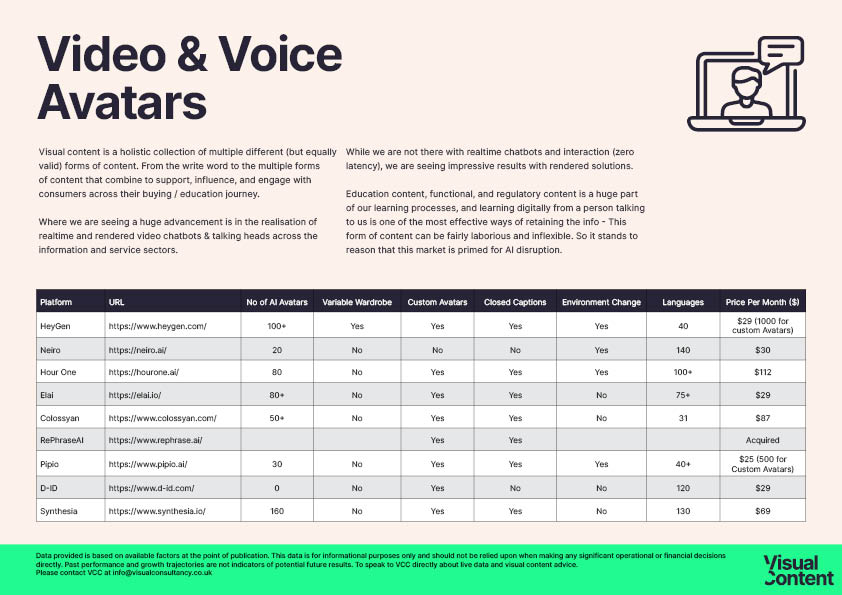
Video & Voice Avatars
This is a fairly common issue when we're talking about video content.
All videos are not made equal! And therefore terminology needs to adapt to reflect the platforms, services, and technologies. As these videoAI workflows and pipelines mature, we're seeing the marketplace fragment with commercial productization - eager to garner swift market share.
New VideoAI platforms drop weekly.
Like most AI advocates our feeds and inboxes are flooded with fresh contenders on a daily basis. Most are iterations on a common theme. Offering true "AI realness"
is left to those understanding what's happening under the hood and how that translates to a commercial production landscape?
As of March 2024, we've been engaging with 73 public VideoAI platforms, including well-known entities like Runway, Pika, Genmo, HeyGen, Pictory, and Stable Video Diffusion, among a raft of others continually emerging through plugins, accelerators, and pivots.
Most platform based solutions are leveraging Stable Diffusion models, and simple distribution channels such as web apps and discord. However, as the users and volumes mature, we seeing a shift towards dedicated websites and more stable mobile applications to improve new user CRO, existing user experience, and improve analytics aligned to the content creation, embed, and RAG training process.
We are all patiently awaiting the launch of platforms leveraging multi-modality, but we're still able to formulate the pipeline and process ready for them to drop! We are developing on node based pipelines to integrate ControlNet's, In and Out painting, and additional IP Adaptors to create compositional and embeddings designed to increase temporal coherence and reduce variation across framing.



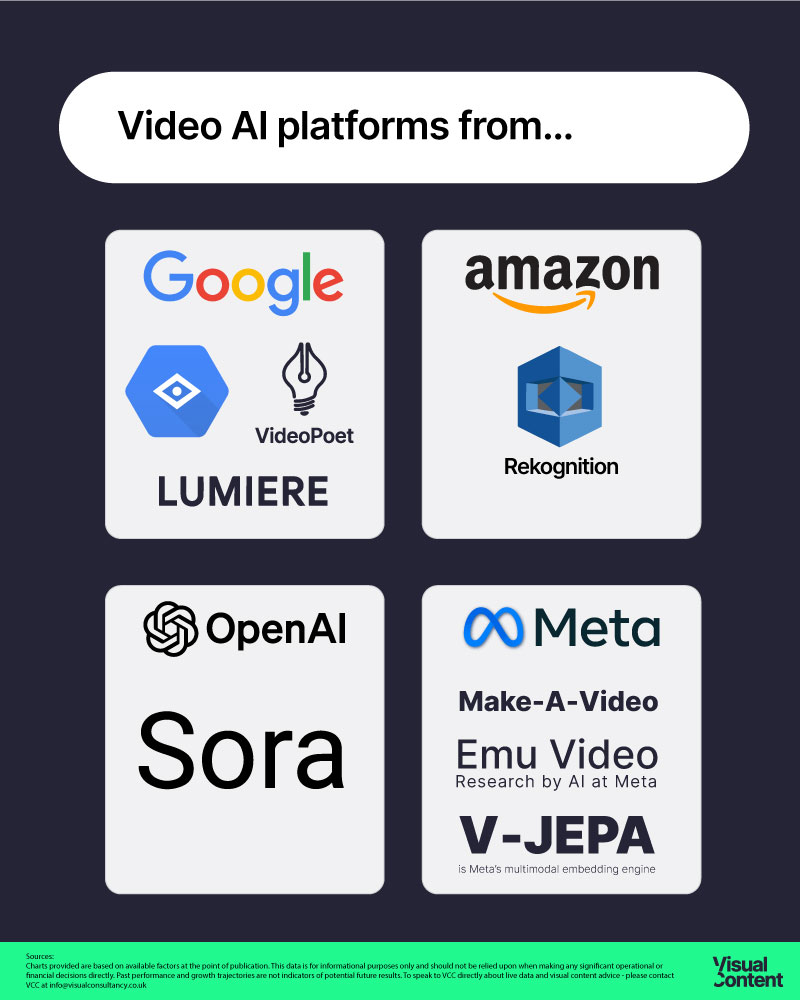
Where are the major tech players?
We haven't seen commercial and experimental videoAI solutions from the major players in technology or AI in 2023. Why is that?
Notably absent in VideoAI 2023 were the tech giants such as Open.ai*, Google, Meta, Amazon, and others, despite their announcements of models like Meta’s Emu Video & Make-a-video, and Google’s VideoPoet & Lumiere, and the raft of Google Vertex (vision) tools.
These companies have largely refrained from releasing their video generation products to the public, choosing instead to focus on research, object detection, image, text, and smattering of example videos. This cautious approach is likely due to legal, safety, consistency, and copyright concerns. Everyone loves to bring the big boys down - these tools need to be far more robust, ethical, and secure at launch than the MVP's.
* we ate our words in Feb didn't we!
Future directions and challenges for VideoAI?
The journey towards fully realising the potential of AI-generated video content is fraught with challenges. So, what's currently stopping this from being the gold rush that imagery was 2 years ago?
Consistency.
I mean we have to start there. With an unprimed and untrained LLM its virtually impossible to achieve temporal coherence in a single video clip - let alone a collection of assets. Where we've been finding success is with T-RAG vector limiters, and finetuning limitations across visual fields.
Understanding directional context.
Humans understand trajectory, velocity, and direction instinctively - but animators train even further to understand the minutia of momentum. The devil is in the uncanny valley of expectation. It's a bit "Newtons second law" - Its easy to see falsity when its not right - but really difficult to explain why its not right.
Therefore, we need a new way of explaining it. A new type of base model, & fine-tuning methodology. This is where we're at now with multi-modality.
Welcome to SORA - who saw that coming?
SORA (from Open.ai) is a massive improvement in the expectation and realisation of video content generation with AI tools. Released in Feb 2024, SORA is the first iteration of what a multimodal system can do. How does it work?
I mean....We'd just finished this article, about to hit 'publish' and Open.ai drops possibly the "news of 2024" with the launch of their offering into the video generation space.
Like Stable Diffusion, Sora is essentially a diffusion model. That means that it starts with each frame of the video consisting of static noise, and transforms this into images through an interpretation of the prompt. SORA is the first model to solve temporal coherence.
Like VFX tweening - The Sora engine is considering several video frames at once, which solves the problem of keeping objects consistent when they move in and out of view. Defining this start and end point at the same time allows the engine to more actually solve for the directional and velocity expectations of the resultant video. Like "automatic rotoscoping" we're using AI tweening to understand the physical parameters of a subject and follow the momentum, not just the action.
So what about the quality?
Well, SORA is combining diffusion and transformer models. In diffusion models, images are broken down into smaller rectangular "patches." For video, these patches are three-dimensional because they have a 'destination' through time. Patches can be thought of as the equivalent of "tokens" in large language models: rather than being a component of a sentence, they are a component of momentum across a set of images. The transformer bit just organises the patches across the known "timeline".
The benefit of this architecture is that it doesn't need to happen on every single pixel for every single frame. Like Stable Cascading - its only scaling the frames later in the process, meaning it's going to be much faster and much more energy efficient.
Increased understanding of the prompting - with recaptioning.
This has been the AI prompt engineers secret sauce for the past few years - this is understanding how to manipulate the language to achieve the desired results.
SORA uses an automatic "recaptioning technique" meaning that before any video is generated, the supporting GPT is rewriting the users prompt to include a lot more model specific detail automatically.
Let's not get too excited. SORA could be a little "Emperors new clothes" too.
As SORA is currently not publicly available, outside of the inner circle, all the examples from SORA are coherent and high quality, but it is unclear how many generations were involved. There is likely a lot of content hitting the 'cutting room floor' for every clip seen in public. But still, the pace and validity of the outputs we are seeing are still orders of magnitude better than commercially available models now.
This is proof that 2024 & multi-modality will influence the way we conceive, generate, optimise, and distribute video content - and as content creators, marketers, and agencies - its down to us to ensure we're exploiting these opportunities in the most creative, effective, and ethical manner.
What's VideoAI content generation going to be used for?
Join me for one final minute, while we think a step further than multi-modality. Beyond the temporal coherence limitations, and into a world of stability in cost (both financially and environmentally)...
What is the future of video content production going to look like in a year?
We're at a very real inflection point with content generation where soon we'll be playing the "guess which is real" game yet again.
The same way we did with illustrations, CGI years ago. And the same way we did with imagery just months ago.
Granted "we are not there yet" is a term I will hear from AI doomers and sceptics - but I'm talking about future potential, opportunities, and the industry in general.
We're fast approaching a level with imagery and CG where they seamlessly augment the content workflows and production pipelines of many creative and production agencies.
We've built acceptance and harmony into working phases of Virtual Production + CGI + digital clean-up + decentralised stock integration + digital upscaling, and augmented these flows into the way we approach ANY content problem.
This is what we'll be doing with VideoAI:
Yes. It will upset the status quo.
Yes. It will displace some current roles.
But it will open the door to so much more potential. This capability will help level the agency playing field.
This is how we're supporting brands, agencies, and production studios at Visual Content Consultancy - we're focusing on combining content modalities, integration, and understanding potential that will effect content production and effectiveness at scale. We're building operational structures for clients to harness AI, CG, VP, and many other acronyms to influence the velocity, value, and volume of content generation.
Subscribe to
our insights:
Select topics and stay current with our latest insights, ideas, and thoughts.
Fancy a coffee and a chat?
If you have a rough brief, drop us a line and we'd be happy to talk through it.
Innovation discovery:
We're great at discovering growth too. Let's chat about a potential collab.

As generative AI models become bigger, it's inevitable that environmental impact is going to influence how we train future models.

How has YouTube changed the rules on disclosure of AI Content & will it affect rankings?

How can small agencies integrate AI into their working pipeline without risking personality?

What does "VideoAI" actually mean? What's the landscape for videoAI companies in 2024?
It works in a similar way to diffusion, but instead of making a single full image - it creates the content in multiple phases.
Salesforce & McKinsey say that 86% Marketers expect GenAI will be in their commercial activities this year.

How will GenAI influence visual creative marketing content, processes, & activities in 2024?

The future of videoSEO is undoubtedly going to be shaped by AI in both analysis and optimisation.

In this article we'll delve into where the Virtual Production industry will develop in 2024.
